

2017年报考执业医师的人数有80万,预测总体及格率约为20%,如果你不比80%的人努力,那么淘汰的很可能就是你。赶紧在剩下的时间里充充电吧!
国家医学考试网官方数据
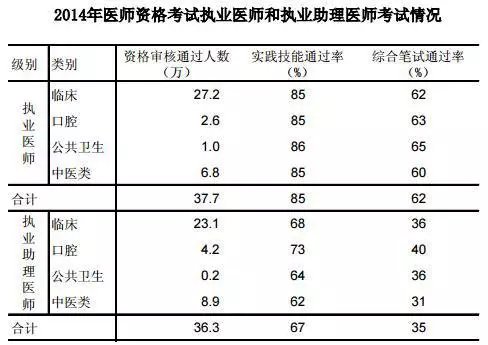
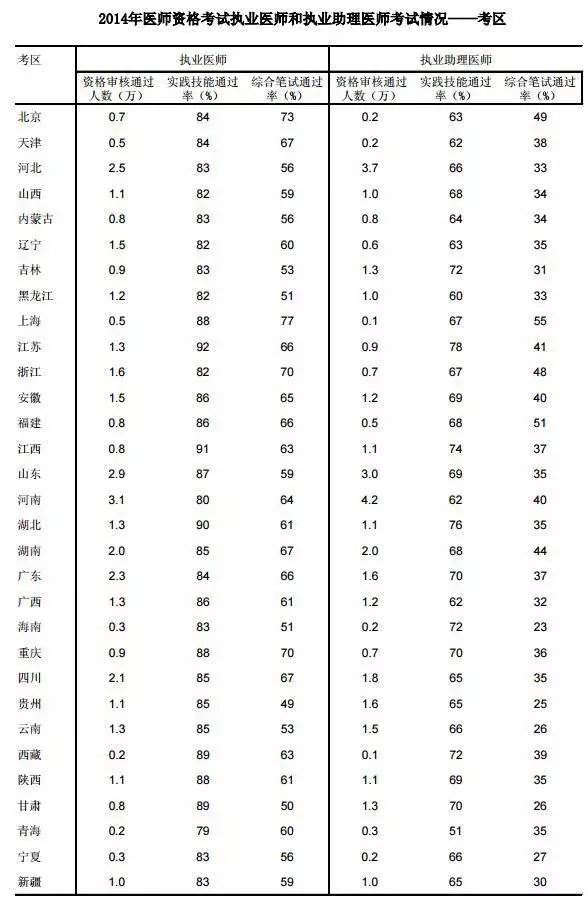
目前全国执业医师资格考试通过率官方数据,在国家医学考试网上只公布过2014年的数据,虽然2015年、2016年的考试情况数据没有公布,但我们可以根据2014的情况作为参考,因为每一年的考试数据变化幅度很小。
历年执业医师考试通过率
2014年执业医师资格考试情况,执业医师资格审核通过人数6.8万,实践技能通过率85%,综合笔试通过率60%,以这个数据参考,可以大体判断出2017年的执业医师考试通过率数据。
通过率最高的学习方法:
执业医师考试难不难,有的人说还比较容易,有的人说很难,有的人甚至连考10年都不过,这其实要看针对的是哪类人群。
如果你刚从学校毕业工作不久,学习能力保持的还不错,自己多努力拿出高考一半的功力通过自学,顺利通过考试应该是大概率事件。
但是,如果你已经参加工作有几年了目前忙于工作没有充分的时间用来学习,或是已经参加过几次考试均没通过,或是你根本没参加过考试不了解考题考点考试大纲。
预防医学必背考点50条
1、 队列研究:由因求果
2、 病例对照研究:由果追因,探索疾病可疑危险因素
3、 健康:是整个身体,精神和社会生活的完好状态,而不仅仅是没有疾病或不虚弱。
4、 健康的影响因素:环境(包括自然环境和社会环境),行为生活方式,医疗卫生服务,生物遗传因素。
5、 三级预防:一级用于病因明确的疾病的预防,如传染病、职业病。二级主要对病因不甚明确的或多病因的疾病采取的预防措施,如肿瘤。三级一般针对病因不明、难以察觉预料的疾病。
6、 统计工作的基本步骤:设计(最关键、决定成败)、搜集资料、整理资料、分析资料。
7、 抽样误差:从总体中随机抽样引起的差异。越小,用样本推断总体的精确度越高。
8、 概率:某事件发生的可能性大小,用P表示,在0-1之间,0和1为肯定不发生和肯定发生,介于0-1之间为偶然事件,
9、 变量:分数值变量和分类变量。
10、 数值变量的特征:对每个观察单位用定量的方式测量其某项特征;变量值是以数值的大小来表示,具有量的连续性,且大多有度量衡单位;由数值变量构成的资料称计量资料。
11、 分类变量的特征:观察结果以事物的属性或类别来表示;变量时不连续的、间断的、各自独立的,没有度量衡单位;分为计数资料和等级资料。12、 描述计量资料的集中趋势的指标:
1均数:适用于正态或近似正态分布;
2几何均数:适用于等比资料,尤其是对数正态分布的计量资料;
3中位数:一组按大小顺序排列的观察值中位次居中的数值,适用于偏态分布资料的集中位置,特别是分布不明、分布末端无确定数据,不能求均数和几何均数,但可求中位数。
13、 描述计量资料的离散趋势的指标:
1全距和四分位数间距:描述一组偏态分布计量资料的变异度;
2方差和标准差:最常用,适于正态分布,开方为标准差 ;
3变异系数(CV):多组间单位不同或均数相差较大的情况,计算公式:CV=s/x*100%,s为样本标准差,x为样本均数。
14、 标准正态分布:均数为0,标准差为1 的正态分布。
15、 样本标准差:反映样本中个观测值变异程度大小的指标,说明了对该样本代表性的强弱;样本标准误:样本平均数的标准差,是抽样误差的估计值,其大小说明样本间变异程度的大小及精确性的高低。
16、 总体率(π)的95%可信区间:p±1.96Sp;
17、 总体率(π)的99%可信区间:p±2.58Sp
18、 统计学检验的无效假设:H0:π1=π2=π3=π4=π5
19、 直线回归方程式:Y=a+bX,a为在Y轴上的截距;b为样本回归系数
20、 直方图:适用于数值变量,连续性资料的频数表资料。
21、 直条图:适用于彼此独立的资料。
22、 发病率:特定人群在一定时间内(一般为一年)发生某病新病例的频率。
23、 罹患率:测量新发病例频率的指标。常用来衡量人群中在较短时间内新发病例的频率,常用于疾病流行或暴发的病因调查。
24、 患病率:常用于慢性病调查统计。
25、 死亡率=死亡数/总人口数 病死率==该病死亡数/该病数
26、 散发:指某病在一定地区的发病率呈现历年来的一般水平,且病例间无明显联系。
27、 流行:指某地区某病发病率明显超过历年的散发发病率水平。
28、 大流行:指疾病蔓延迅速、涉及地域广,在短时间内可越过省界、国界、甚至洲界的情况。(迅速、大范围)
29、 暴发:在一个局部地区或集中单位中,短时间内突然有很多相同的患者出现。(局部。迅速)
30、 系统抽样:按照一定顺序,机械的每隔一定数量的单位抽取一个单位,又称间隔抽样或机械抽样。
31、 分层抽样:先将研究对象按主要特征分为几层,然后再在各层中进行随机抽样,用以组成调查的样本。
32、 现况调查的目的:描述疾病后健康状况于特定时间内在某地区人群中分布情况及影响分布的因素,描述某些因素或特征与疾病之间的关系,寻找病因及流行因素线索,进行疾病监测,早期发现病人,早期诊断和早期治疗。
33、 病例对照:比值比OR=ad/bc,=1无关联,>1正关联,暴露是疾病的危险因素,<1负关联,保护因素
34、 常见偏倚:选择偏倚(包括入院率偏倚、错误分析偏倚、检出症候偏倚、无应答偏倚、患病率及发病率偏倚),信息偏倚,混杂偏倚。
35、 队列研究:是选定暴露和未暴露于某因素的两种人群,追踪其各自的发病结局,比较两者发病结局的差异,从而判断暴露因素与发病有无因果关联及关联大小的一种观察性研究方法。用于检验病因假设,描述疾病的自然史。
36、 相对危险度(RR):暴露组发病或死亡是非暴露组的倍数。RR=a/(a+b)/c/(c+d),=1无关联,>1正关联,暴露是疾病的危险因素;<1负关联,保护因素
37、 归因危险度(AR):暴露组发病率和非暴露组发病率的差,AR=a/(a+b)-c/(c+d)
38、 临床试验效果主要评价指标:有效率=有效治疗例数/治疗的总例数x100%治愈率=治愈人数/治疗人数x100%生存率=X年存活的病例数/随访满X年的生存率保护率=[对照组发病(死亡)率-实验组发病(死亡)率]/对照组发病(死亡)率效果指数=对照组发病(死亡)率/实验组发病(死亡)率x100%
39、 确定因果关联的标准:关联的强度、普遍性、特异性、时间顺序(必需)、分布一致性,剂量-反应关系、实验依据、合理性、相似性。
40、 灵敏度=a/a+c ,有病的人被判断出来的能力
41、 假阴性率
42、 特异度(真阴性)=d/b+d;没有病的人被判断为无病的能力
43、 假阳性率=b/b+d;实际无病的人被判断为有病的人
44、 营养素需要量:指维持人体正常健康与生长所需要营养素的数量。
45、 营养素供给量(RDA):指特定人群每日必须通过膳食摄取个营养素的标准。
46、 食物中蛋白质含量:测定含氮量x6.25;干大豆类最高,粮谷类较低。
47、 必需氨基酸:“携一两本单色书来” 缬氨酸、异亮氨酸、亮氨酸、苯丙氨酸、蛋氨酸、色氨酸、苏氨酸、赖氨酸;对婴儿来说组氨酸也是必需氨基酸。
48、 谷类:富含蛋氨酸,缺乏赖氨酸;豆类富含赖氨酸而缺乏蛋氨酸,混合食用可提高生物学价值。
49、 必需脂肪酸:植物油中含量较多(椰子油除外),动物脂肪中含量较少(鱼油除外)。
50、 铁的来源:动物肝脏、全血、鱼类、肉类。






